Capitolo 2 Variabili Statistiche e Distribuzioni di Frequenza
2.1 Variabili Statistiche
Una Variabile Statistica (VS) è una qualunque caratteristica osservabile sugli individui (unità statistiche) della popolazione di riferimento, che varia da individuo ad individuo.
2.1.1 Notazione di Base
- \(\mathbf{x}=(x_1,x_2,...,x_i,...,x_n)\), etichette simboliche per i dati, il primo dato osservato, il secondo ecc.
- \(i\), indice che conta le osservazioni nell’ordine in cui sono state osservate
- \(i\in\{1,2,...,n\}\)
- il primo, il secondo, … l’\(i\)-esimo, … l’\(n\)-esimo (l’ultimo)
- \(n\), numerosità assoluta: il numero totale di individui osservati.
- \(S_X=\{\mathrm{x}_1,...,\mathrm{x}_j,...,\mathrm{x}_K\}\), l’insieme di tutte le modalità possibili che la variabile statistica è suscettibile di assumere.
- \(j\), indice che conta le modalità: prima, seconda, …, \(j\)-esima,…, la \(K\)-esima.
- \(K\), numero di modalità.
Esempio 2.1 (Variabile: genere) \(\phantom{.}\)
- \(\mathbf{x}=(x_1 = M, x_2 =F, x_3 =M, x_4=F,x_5=F,x_6=F)\)
- \(n=6\)
- \(S_X=\{\mathrm{x}_1 = F,\mathrm{x}_2 = M\}\)
- \(K=2\)
Esempio 2.2 (Variabile: titolo di studio) \(\phantom{.}\)
- \(\mathbf{x}=(x_1 = E, x_2 =M, x_3 =L, x_4=S,x_5=S,x_6=S, x_7=L,x_8=M,x_9=L,x_{10}=S)\)
- \(n=10\)
- \(S_X=\{\mathrm{x}_1 = E,\mathrm{x}_2 = M, \mathrm{x}_3=S,\mathrm{x}_4=L\}\)
- \(K=4\)
Esempio 2.3 (Variabile: Numero di interventi di manutenzione giornalieri) \(\phantom{.}\)
- \(\mathbf{x}=(x_1 = 0, x_2 =1, x_3 =0, x_4=2,x_5=1,x_6=1, x_7=0,x_8=1,x_9=3,x_{10}=1)\)
- \(n=10\)
- \(S_X=\{\mathrm{x}_1 = 0,\mathrm{x}_2 = 1,\mathrm{x}_3=2,\mathrm{x}_4=3,...\}\)
- \(K=+\infty\)
2.1.2 Ordinamento e conteggio
Se l’ordine di osservazione non è influente ai fini della conoscenza del fenomeno i dati possono essere permutati (mescolati) a piacimento, la sequenza:
\[(x_{(1)},x_{(2)},...,x_{(i)},...,x_{(n)}),\]
indica i dati riordinati, dal più piccolo, al più grande. Se i dati sono numerici l’ordinamento è univoco, se i dati sono categoriali l’ordinamento è arbitrario.
Esempio 2.4 (Continua) Continuiamo l’esempio della variabile genere discussa nell’esempio 2.1
- \(\mathbf{x}=(x_1 = M, x_2 =F, x_3 =M, x_4=F,x_5=F,x_6=F)\)
- \(S_X=\{\mathrm{x}_1 = F,\mathrm{x}_2 = M\}\)
- \(x_{(1)}=F,x_{(2)}=F,x_{(3)}=F,x_{(4)}=F,x_{(5)}=M,x_{(6)}=M\)
Esempio 2.5 (Continua: codifica 0, 1) \(\phantom{.}\)
- Variabile: genere {M -> 0,F-> 1}
- \(\mathbf{x}=(x_1 = 0, x_2 =1, x_3 =0, x_4=1,x_5=1,x_6=1)\)
- \(S_X=\{\mathrm{x}_1 = 0,\mathrm{x}_2 = 1\}\)
- \(x_{(1)}=0,x_{(2)}=0,x_{(3)}=1,x_{(4)}=1,x_{(5)}=1,x_{(6)}=1\)
- nota: nella codifica 0, 1 ha senso sommare i dati: \[x_1+x_2+x_3+x_4+x_6=4,~~\text{Numero di femmine}\]
Esempio 2.6 (Continua: Variabile titolo di studio) \(\phantom{.}\)
- \(\mathbf{x}=(x_1 = E, x_2 =M, x_3 =L, x_4=S,x_5=S,x_6=S, x_7=L,x_8=M,x_9=L,x_{10}=S)\)
- \(S_X=\{\mathrm{x}_1 = E,\mathrm{x}_2 = M, x_3=S, x_4=L\}\)
- \(x_{(1)}=E,x_{(2)}=M,x_{(3)}=M,x_{(4)}=S,x_{(5)}=S,x_{(6)}=S,x_{(7)}=S,x_{(8)}=L,x_{(9)}=L, x_{(10)}=L\)
Esempio 2.7 (Continua: Codifica Numerica) \(\phantom{.}\)
- Variabile: titolo di studio {E -> 1, M -> 2, S -> 3, L -> 4}
- \(\mathbf{x}=(x_1 = 1, x_2 = 2, x_3 = 4, x_4= 3,x_5=3,x_6=3, x_7=4,x_8=2,x_9=4,x_{10}=3)\)
- \(S_X=\{\mathrm{x}_1 = 1,\mathrm{x}_2 = 2, x_3=3, x_4=4\}\)
- \(x_{(1)}=1,x_{(2)}=2,x_{(3)}=2,x_{(4)}=3,x_{(5)}=3,x_{(6)}=3,x_{(7)}=3,x_{(8)}=4,x_{(9)}=4, x_{(10)}=4\)
- ha senso sommare i dati?
La codifica numerica corretta sarebbe più complessa
| E | M | S | L | |
|---|---|---|---|---|
| \(x_1\) | 1 | 0 | 0 | 0 |
| \(x_2\) | 0 | 1 | 0 | 0 |
| \(x_3\) | 0 | 0 | 0 | 1 |
| \(x_4\) | 0 | 0 | 1 | 0 |
| \(x_5\) | 0 | 0 | 1 | 0 |
| \(x_6\) | 0 | 0 | 1 | 0 |
| \(x_7\) | 0 | 0 | 0 | 1 |
| \(x_8\) | 0 | 1 | 0 | 0 |
| \(x_9\) | 0 | 0 | 0 | 1 |
| \(x_{10}\) | 0 | 0 | 1 | 0 |
| \(Tot\) | 1 | 2 | 4 | 3 |
I totali di colonna hanno senso e indicano il numero di individui che ha un determinato titolo di studio.
Questa codifica è sovra abbondante infatti come per maschio e femmina possiamo contare solo un colonna di presenza 1 (è femmina) e assenza 0 (non è femmina e quindi maschio), per una variabile a 4 modalità possiamo contare solo 3, ad esempio
- 0,0,0 elementari
- 1,0,0 medie
- 0,1,0 superiori
- 0,0,1 università
| M | S | L | |
|---|---|---|---|
| \(x_1\) | 0 | 0 | 0 |
| \(x_2\) | 1 | 0 | 0 |
| \(x_3\) | 0 | 0 | 1 |
| \(x_4\) | 0 | 1 | 0 |
| \(x_5\) | 0 | 1 | 0 |
| \(x_6\) | 0 | 1 | 0 |
| \(x_7\) | 0 | 0 | 1 |
| \(x_8\) | 1 | 0 | 0 |
| \(x_9\) | 0 | 0 | 1 |
| \(x_{10}\) | 0 | 1 | 0 |
| \(Tot\) | 2 | 4 | 3 |
Per sapere il numero persone che ha al massimo le elementari basta fare 10 (numero totale di individui) meno 2 (medie) più 4 (superiori) più 3 (laureati):
\[ 10-(2+4+3)=1~~~\text{con le elemntari} \]
Esempio 2.8 (Continua: Numero di interventi di manutenzione giornalieri) \(\phantom{.}\)
- \(\mathbf{x}=(x_1 = 0, x_2 =1, x_3 =0, x_4=2,x_5=1,x_6=1, x_7=0,x_8=1,x_9=3,x_{10}=1)\)
- \(S_X=\{\mathrm{x}_1 = 0,\mathrm{x}_2 = 1,\mathrm{x}_3=2,\mathrm{x}_4=3,...\}\)
- \(x_{(1)}=0,x_{(2)}=0,x_{(3)}=0,x_{(4)}=1,x_{(5)}=1,x_{(6)}=1,x_{(7)}=1,x_{(8)}=1,x_{(9)}=2, x_{(10)}=3\)
- ha senso sommare i dati?
- cosa rappresenta la somma dei dati?
Esempio 2.9 (Ore uomo dedicate a interventi di manutenzione) \(\phantom{.}\)
Supponiamo di aver collezionato il numero di ore uomo (e frazioni di ora) dedicate ad ogni intervento di manutenzione L’unità statistica sarà l’intervento, \(i=1\) il primo, \(i=2\), il secondo, ecc. e assumerà un valore decimale \(x_3=3.5\) significa che la terza manutenzione ha impiegato un addetto per 3 ore e mezza.
- \(\mathbf{x}=(x_1 = 0.4, x_2 =2.7, x_3 =3.5, x_4=1.4,x_5=4.3,x_6=4.6, x_7=0.2,x_8=1.9,x_9=3.4,x_{10}=0.1)\)
- \(S_X=\{\mathrm{x}_1 = 0.0,\mathrm{x}_2 = 0.1,\mathrm{x}_3=0.2,\mathrm{x}_4=0.3,...\}\)
- \(x_{(1)}=0.1, x_{(2)}=0.2, x_{(3)}=0.4, x_{(4)}=1.4, x_{(5)}=1.9, x_{(6)}=2.7, x_{(7)}=3.4, x_{(8)}=3.5, x_{(9)}=4.3, x_{(10)}=4.6\)
- ha senso sommare i dati?
- cosa rappresenta la somma dei dati?
2.1.3 Le unità di misura
In statistica, ogni dato è sempre espresso in una specifica unità di misura, che conferisce significato al valore numerico registrato. Le unità di misura variano in base alla natura dei dati e al fenomeno osservato, e possono includere:
Conteggi: I dati che rappresentano quantità possono essere espressi in unità di conteggio, come unità singole, decine, centinaia, migliaia, ecc. Ad esempio, se registriamo il numero di visitatori in un parco in un anno, può essere più comodo esprimere 12.000 visitatori come “12 migliaia” (12 x 1000), facilitando la lettura. Analogamente, 1.200 prodotti venduti potrebbero essere espressi come “1,2 migliaia” per rendere i confronti immediati tra dati di grandezza diversa.
Misure metriche: Le grandezze fisiche come la lunghezza, la massa, la capacità e la temperatura sono espresse in unità metriche, come metri, chilogrammi, e litri. Ad esempio, per confrontare il peso di vari articoli, un dato in grammi potrebbe risultare scomodo se molto elevato; per articoli pesanti, come \(12~000\) grammi, potrebbe essere più leggibile esprimere il dato in chilogrammi come 12 kg, dove 1 kg = \(1~000\) grammi. Questo cambio di unità mantiene invariato il rapporto tra le osservazioni, facilitando la comprensione e l’analisi.
Misure derivate o di rapporto: Alcune unità di misura rappresentano rapporti tra grandezze, come chilometri all’ora (km/h) per la velocità, o litri per 100 chilometri (L/100 km) per il consumo di carburante. Ad esempio, se un’auto consuma 7 litri ogni 100 km, esprimere il consumo in questa unità (7 L/100 km) è più immediato e rappresentativo di un valore medio, rispetto all’uso di litri per singolo chilometro (0.07 L/km), che potrebbe risultare poco intuitivo.
Misure di risultati e punteggi: In statistica, si usano spesso trasformazioni che combinano più misure per produrre un indicatore con una scala di misura propria, utile per confrontare sinteticamente informazioni complesse. Consideriamo la seguente formula generale: \[ x_i = f(a_{i1}, a_{i2}, a_{i3}, \dots) \] dove \(a_{ij}\) rappresenta le varie misure o statistiche che contribuiscono al calcolo del valore \(x_i\), cioè l’indicatore della i-esima osservazione. Per esempio, immaginiamo di voler calcolare un punteggio di idoneità per i candidati a un lavoro, basato su tre misure diverse:
- \(a_{i1}\): esperienza in anni,
- \(a_{i2}\): punteggio di un test tecnico (da 0 a 100),
- \(a_{i3}\): valutazione del colloquio (da 0 a 5).
Per produrre un indicatore che misuri l’idoneità complessiva su una scala uniforme, potremmo usare una formula come: \[ x_i = 0.5 \cdot a_{i1} + 0.3 \cdot a_{i2} + 2 \cdot a_{i3} \] Questa formula pondera ciascuna misura per dare maggiore peso all’esperienza (0.5) e al colloquio (2) rispetto al test tecnico (0.3). Per il quinto candidato (\(i=5\)) con 5 anni di esperienza, un punteggio di 80 al test e una valutazione di 4 al colloquio, il punteggio di idoneità risulterebbe: \[ x_5 = 0.5 \cdot 5 + 0.3 \cdot 80 + 2 \cdot 4 = 2.5 + 24 + 8 = 34.5 \] In questo caso, il punteggio di idoneità \(x_i\) è su una scala propria, definita dalle scelte di peso e dalle unità combinate, e consente di confrontare i candidati in modo sintetico, anche se ogni componente ha un’unità di misura diversa.
2.1.4 Trasformazioni lineari
In matematica e statistica, una trasformazione lineare è un’operazione che modifica i dati mantenendo invariati i rapporti tra le osservazioni. La forma generale di una trasformazione lineare è:
\[ y_i = a + b x_i \]
dove: - \(x_i\) rappresenta la misura i-esima del dato originale. - \(a\) rappresenta uno spostamento dell’origine (traslazione), che posiziona i dati su un nuovo punto di partenza, spostando l’intero grafico verso l’alto o verso il basso. - \(b\) è il fattore di scala, che ridimensiona i valori, influenzando la pendenza della retta. Un fattore maggiore di 1 espande i valori, mentre uno tra 0 e 1 li contrae.
Geometricamente, il termine \(a\) trasla il grafico lungo l’asse verticale senza modificare le distanze relative tra i punti, mentre \(b\) varia la pendenza, allargando o comprimendo i dati rispetto all’origine.
2.1.4.1 Cambiamento di scala come trasformazione lineare
Un cambiamento di scala è una trasformazione lineare applicata a ogni misura i-esima del dato, che permette di adattare l’unità di misura senza alterare i rapporti tra le osservazioni. Vediamo alcuni esempi pratici.
Esempio 2.10 (Ore uomo dedicate a interventi di manutenzione) Supponiamo di avere i dati su diverse spese in euro e di volerli esprimere in migliaia di euro per facilitare la lettura. La trasformazione è:
\[ y_i = \frac{1}{1000} \cdot x_i \]
Dove \(x_i\) è il valore in euro della misura i-esima e \(y_i\) è il valore corrispondente in migliaia di euro. Per chiarire questo concetto, prendiamo \(i=4\) con \(x_4 = 12~000\):
\[ y_4 = \frac{1}{1000} \cdot 12~000 = 12 \]
Quindi, invece di esprimere la quarta misura come \(12~000\) euro, la rappresentiamo come 12 migliaia di euro, semplificando la gestione e la comparabilità dei dati.
Esempio 2.11 (Ore uomo dedicate a interventi di manutenzione) Anche la conversione da gradi Celsius (\(C\)) a gradi Fahrenheit (\(F\)) segue una trasformazione lineare, espressa come:
\[ F_i = 32 + \frac{9}{5} \cdot C_i \]
Qui, il termine 32 rappresenta uno spostamento dell’origine, poiché 0 °C corrisponde a 32 °F, mentre il fattore \(\frac{9}{5}\) espande i valori per adattarsi alla scala Fahrenheit. Ad esempio, se \(i=2\) e \(C_2 = 25\):
\[ F_2 = 32 + \frac{9}{5} \cdot 25 = 32 + 45 = 77 \]
Questa trasformazione mantiene la proporzionalità tra le temperature, adattando la scala e le unità di misura.
2.2 Distribuzione di Frequenza
La frequenza indica quanto una modalità insiste sul collettivo. Le frequenze si dividono in:
Definizione 2.1 (Frequenze Assolute) Si definiscono le \(n_j\) le frequenze assolute: il numero di individui che presentano la modalità \(j\).
Definizione 2.2 (Frequenze Relative) Si definiscono le \(f_j=n_j/n\) le frequenze relative: la proporzione di individui che presentano la modalità \(j\).
Definizione 2.3 (Frequenze Percentuali) Si definiscono le \(f_{\% j}=f_j\times 100\) le frequenze percentuali: la percentuale di individui che presentano la modalità \(j\).
Proprietà 2.1 Le proprietà della frequenze assolute(\(n_{j}\)) sono:
- \(0\leq n_{j} \leq n, \forall j=1,...,K\),
- \(\sum_{j=1}^{K} n_{j} = n\).
Proprietà 2.2 Le proprietà della frequenze relative (\(f_{j}\)) sono:
- \(0\leq f_{j} \leq 1, \forall j=1,...,K\),
- \(\sum_{j=1}^{K} f_{j} = 1\).
Proprietà 2.3 Le proprietà della frequenze percentuali (\(f_{\% j}\)) sono:
- \(0\leq f_{\%,\, j} \leq 100, \forall j=1,...,K\),
- \(\sum_{j=1}^{K} f_{\%,\, j} = 100\).
Definizione 2.4 (Distribuzione di Frequenza) Una distribuzione di frequenza è una tabella a cui vengono associate le modalità e le frequenze
Esempio 2.12 (Continua: Variabile: genere) \[x_{(1)}=F,x_{(2)}=F,x_{(3)}=F,x_{(4)}=F,x_{(5)}=M,x_{(6)}=M\]
| \(X\) | \(n_j\) | \(f_j\) | \(f_{\% j}\) |
|---|---|---|---|
| F | \(4\) | \(4/6=0.67\) | \(67\%\) |
| M | \(2\) | \(2/6=0.33\) | \(33\%\) |
| Tot | \(6\) | \(1.00\) | \(100\%\) |
Esempio 2.13 (Continua: Variabile titolo di studio) \(\phantom{.}\)
\(x_{(1)}=E,x_{(2)}=M,x_{(3)}=M,x_{(4)}=S,x_{(5)}=S,x_{(6)}=S,x_{(7)}=S,x_{(8)}=L,x_{(9)}=L, x_{(10)}=L\)
| \(X\) | \(n_j\) | \(f_j\) | \(f_{\% j}\) |
|---|---|---|---|
| E | \(2\) | \(2/20=0.1\) | \(10\%\) |
| M | \(4\) | \(4/20=0.2\) | \(20\%\) |
| S | \(8\) | \(8/20=0.4\) | \(40\%\) |
| L | \(6\) | \(6/20=0.3\) | \(30\%\) |
| Tot | \(20\) | \(1.0\) | \(100\%\) |
2.2.1 Dati quantitativi continui
Se i dati sono quantitativi continui il numero delle modalità è spesso di gran lunga superiore al numero dei dati e non sempre è possibile fissare un limite superiore in anticipo all’osservazione dei dati. Se per esempio volessi misurare il reddito di una persona in centesimi, otterrei:
Esempio 2.14 (Variabile: Reddito mensile lordo in migliaia di euro) \(\phantom{x}\)
- unità di rilevazione: famiglie del comune A a febbraio 2021
- \(n=45\)
- \(S_X=\{0.00,0.01,0.02,...,100.00,100.01,...,2000.00,...,10~000,...\}\)
Qui di seguito i dati nell’ordine in cui sono stati raccolti è sono mostrati sopra, mentre i dati riordinati sono mostrati sotto:
\[\begin{array}{crcrcrcrcr} \hline x_{1}= & 2.13 & x_{10}= & 3.08 & x_{19}= & 4.73 & x_{28}= & 7.31 & x_{37}= & 14.54 \\ x_{2}= & 0.74 & x_{11}= & 4.32 & x_{20}= & 4.36 & x_{29}= & 6.65 & x_{38}= & 10.52 \\ x_{3}= & 1.17 & x_{12}= & 4.76 & x_{21}= & 3.27 & x_{30}= & 8.17 & x_{39}= & 17.59 \\ x_{4}= & 0.27 & x_{13}= & 4.78 & x_{22}= & 4.09 & x_{31}= & 7.12 & x_{40}= & 10.84 \\ x_{5}= & 2.89 & x_{14}= & 4.13 & x_{23}= & 4.36 & x_{32}= & 7.03 & x_{41}= & 16.04 \\ x_{6}= & 0.03 & x_{15}= & 4.19 & x_{24}= & 4.06 & x_{33}= & 9.59 & x_{42}= & 12.30 \\ x_{7}= & 1.72 & x_{16}= & 3.73 & x_{25}= & 3.17 & x_{34}= & 9.04 & x_{43}= & 19.67 \\ x_{8}= & 2.29 & x_{17}= & 3.71 & x_{26}= & 8.10 & x_{35}= & 7.70 & x_{44}= & 16.05 \\ x_{9}= & 2.62 & x_{18}= & 4.18 & x_{27}= & 5.16 & x_{36}= & 11.07 & x_{45}= & 16.40 \\ \hline x_{(1)}= & 0.03 & x_{(10)}= & 3.08 & x_{(19)}= & 4.19 & x_{(28)}= & 7.03 & x_{(37)}= & 10.84 \\ x_{(2)}= & 0.27 & x_{(11)}= & 3.17 & x_{(20)}= & 4.32 & x_{(29)}= & 7.12 & x_{(38)}= & 11.07 \\ x_{(3)}= & 0.74 & x_{(12)}= & 3.27 & x_{(21)}= & 4.36 & x_{(30)}= & 7.31 & x_{(39)}= & 12.30 \\ x_{(4)}= & 1.17 & x_{(13)}= & 3.71 & x_{(22)}= & 4.36 & x_{(31)}= & 7.70 & x_{(40)}= & 14.54 \\ x_{(5)}= & 1.72 & x_{(14)}= & 3.73 & x_{(23)}= & 4.73 & x_{(32)}= & 8.10 & x_{(41)}= & 16.04 \\ x_{(6)}= & 2.13 & x_{(15)}= & 4.06 & x_{(24)}= & 4.76 & x_{(33)}= & 8.17 & x_{(42)}= & 16.05 \\ x_{(7)}= & 2.29 & x_{(16)}= & 4.09 & x_{(25)}= & 4.78 & x_{(34)}= & 9.04 & x_{(43)}= & 16.40 \\ x_{(8)}= & 2.62 & x_{(17)}= & 4.13 & x_{(26)}= & 5.16 & x_{(35)}= & 9.59 & x_{(44)}= & 17.59 \\ x_{(9)}= & 2.89 & x_{(18)}= & 4.18 & x_{(27)}= & 6.65 & x_{(36)}= & 10.52 & x_{(45)}= & 19.67 \\ \hline \end{array}\]
Come si osserva aver rimesso in ordine i dati non ci aiuta a capire la distribuzione del fenomeno.
2.2.2 Raggruppamenti in Classi
L’idea è quella di raggruppare i dati in intervalli contigui e procedere alla rappresentazione in distribuzione di frequenza. In tabella 2.1 vediamo a sinistra troppe poche classi, al centro troppe, mentre a destra vediamo che il numero delle classi e la loro ampiezza variabile rende più leggibile la distribuzione dei dati.
|
|
|
2.2.3 Frequenze Cumulate
Si definisce frequenza cumulata \(F\) la seguente quantità:
- \(F_1 = f_1\)
- \(F_2= f_1+f_2=F_1+f_2\)
- \(F_3= f_1+f_2+f_3=F_2+f_3\)
- …
- \(F_j= f_1+f_2+...+f_j=F_{j-1}+f_j\)
- …
- \(F_K= f_1+f_2+...+f_K=1\)
ovvero \(F_j=f_1+...+f_j\) cumula tutte le frequenze dalla 1 alla \(j\).
Esempio 2.15 (Continua: Variabile titolo di studio) \(\phantom{.}\)
| \(n_j\) | \(f_j\) | \(F_j\) | |
|---|---|---|---|
| E | 1 | 0.1 | 0.1 |
| M | 2 | 0.2 | 0.3 |
| S | 4 | 0.4 | 0.7 |
| U | 3 | 0.3 | 1.0 |
E si legge: \(F_1=0.1\) ci dice che il 10% del collettivo in esame ha come massimo titolo ha non più delle elementari. \(F_1=0.3\) ci dice che il 30% del collettivo ha come massimo titolo ha non più delle medie. \(F_4=0.7\) ci dice che il 30% del collettivo ha come massimo titolo ha non più delle superiori e \(F_5=1\) che il 100% del collettivo ha, al massimo, la laurea.
Esempio 2.16 (Continua: Reddito) \(\phantom{.}\)
| \([\text{x}_j,\) | \(\text{x}_{j+1})\) | \(f_j\) | \(F_j\) |
|---|---|---|---|
| 0 | 3 | 0.20 | 0.20 |
| 3 | 5 | 0.36 | 0.56 |
| 5 | 10 | 0.22 | 0.78 |
| 10 | 20 | 0.22 | 1.00 |
| 1.00 |
E si legge: \(F_1=0.21\) ci dice che il 20% del collettivo in esame guadagna al massimo 3 (mila euro); alternativamente leggiamo che il 20% del collettivo non guadagna più di 3 (mila euro). \(F_2=0.56\) ci dice che il 56% del collettivo guadagna al massimo 5. \(F_2=0.56\) ci dice che il 56% del collettivo guadagna al massimo 5 (mila euro); il 56% non guadagna più di 5 (mila euro). \(F_3=0.78\) ci dice che il 78% del collettivo guadagna 10 (mila euro); il 78% non guadagna più di 10 (mila euro). E infine il 100% del collettivo guadagna al massimo 20 (mila euro).
2.3 Istogramma di Densità
È grafico che rappresenta rettangoli contigui la cui area è la frequenza e la base è l’intervallo di raggruppamento. Usiamo il simbolo \(b_j\) per denotare l’ampiezza della base del rettangolo, l’altezza dei rettangoli viene chiamata densità
\[h_j = Const.\times \frac {f_j} {b_j}\]
Se \(Const.=1\) si ottiene l’istogramma di densità relativa, la somma delle aree dei rettangoli è 1. Se \(Const.=n\) si ottiene l’istogramma di densità assoluta, la somma delle aree dei rettangoli è \(n\). Se \(Const.=100\) si ottiene l’istogramma di densità percentuale, la somma delle aree dei rettangoli è 100. Per comodità tutti gli esempi si riferiscono all’istogramma di densità percentuale.
| \([\text{x}_j\), | \(\text{x}_{j+1})\) | \(n_j\) | \(f_j=\frac{n_j}{n}\) | \(b_j=\text{x}_{j+1}-\text{x}_{j}\) | \(h_j=100\times\frac{f_j}{b_j}\) |
|---|---|---|---|---|---|
| \([\text{x}_1=0\), | \(\text{x}_{2}=3)\) | \(n_1=9\) | \(f_1=\frac {n_1} n =\frac 9{45}=0.20\) | \(b_1=3-0=3\) | \(h_1=100\times\frac{0.20}{3}=6.67\) |
| \([\text{x}_2=3\), | \(\text{x}_{3}=5)\) | \(n_2=16\) | \(f_2=\frac {n_2} n =\frac {16}{45}=0.36\) | \(b_2=5-3=2\) | \(h_2=100\times\frac{0.36}{2}=17.78\) |
| \([\text{x}_3=5\), | \(\text{x}_{4}=10)\) | \(n_3=10\) | \(f_3=\frac {n_3} n =\frac {10}{45}=0.22\) | \(b_3=10-5=5\) | \(h_3=100\times\frac{0.22}{5}=4.44\) |
| \([\text{x}_4=10\) | \(\text{x}_{5}=20)\) | \(n_4=10\) | \(f_4=\frac {n_4} n =\frac {10}{45}=0.22\) | \(b_4=20-10=10\) | \(h_4=100\times\frac{0.22}{10}=2.22\) |
Esempio 2.17 La tabella 2.2 mostra passo, passo lo sviluppo del calcolo. La figura 2.1 la corrispondente rappresentazione grafica.
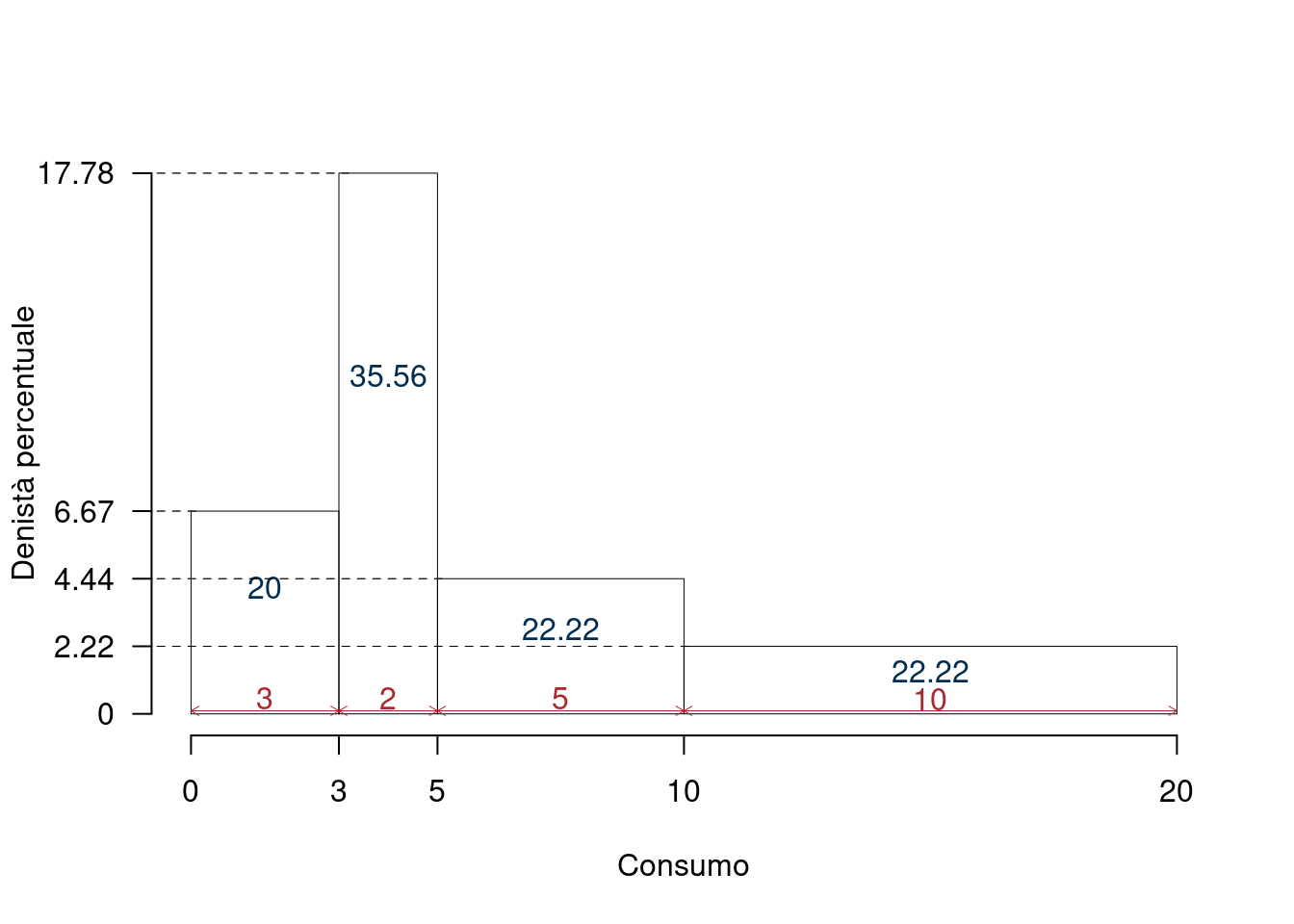
Figura 2.1 Rappresentazione grafica dell’istogramma di densità percentuale, l’area di ogni rettangolo corrisponde alla frequenza percentuale della classe, rappresentata sull’asse delle ascisse
2.4 La Funzione di Ripartizione
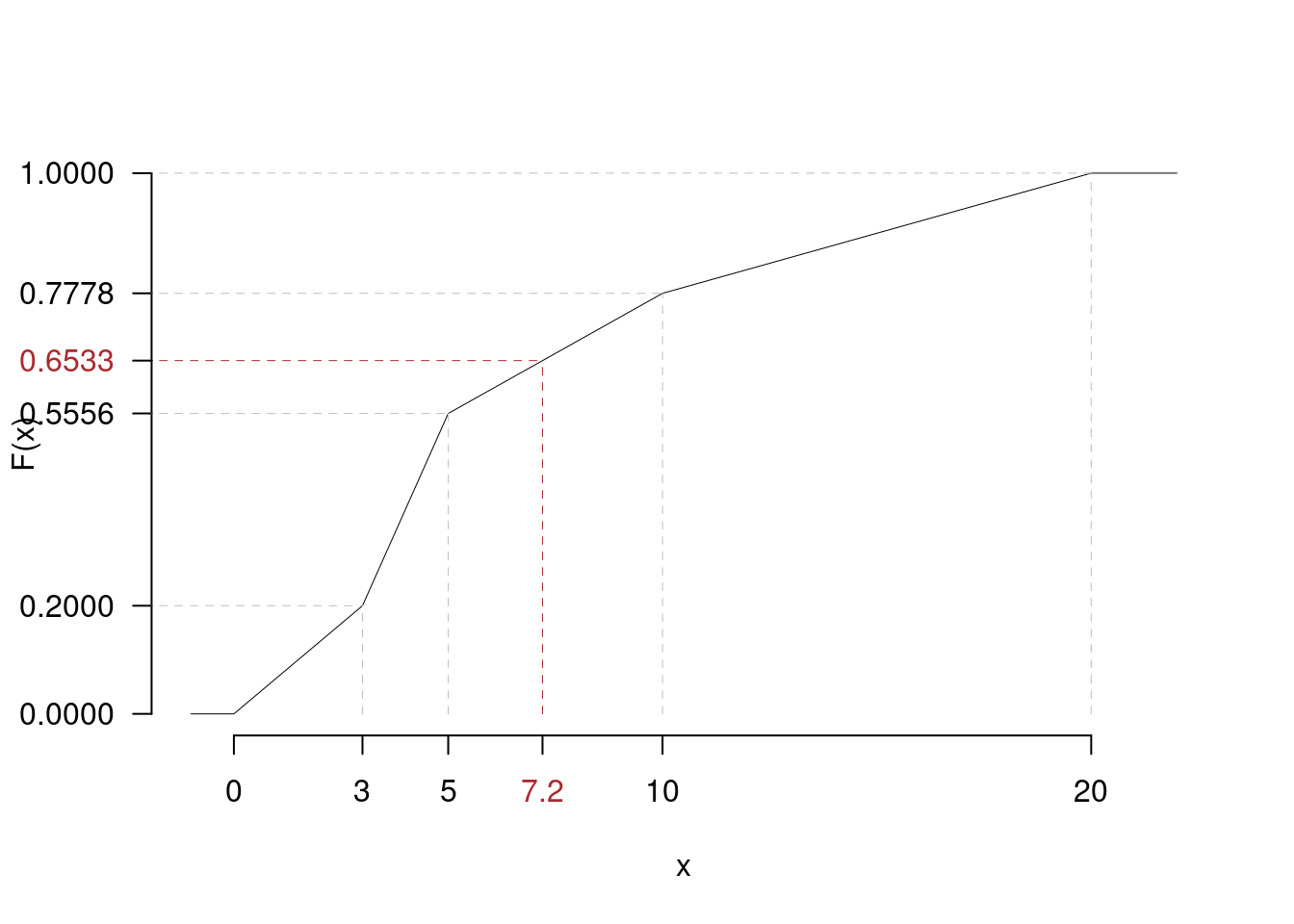
Se i dati sono quantitativi continui raggruppati in classi, la Funzione di Ripartizione della VS \(X\) è la funzione che misura l’area dell’istogramma di densità (le aree sommano ad 1) dal più piccolo dei dati \(x_{(0)}\) fino ad un \(x\) qualunque. Se nel caso dell’esempio precedente scegliessimo \(x=7.2\), graficamente vedremmo la figura 2.2. Notiamo innanzitutto che:
\[\begin{eqnarray*} F(\text{x}_1)&=& 0\\ F(\text{x}_2) &=& F_1\\ F(\text{x}_3) &=& F_2\\ \vdots~~~ && \vdots\\ F(\text{x}_j) &=& F_{j-1}\\ \vdots~~~ && \vdots\\ F(\text{x}_{K+1}) &=& 1 \end{eqnarray*}\]
Figura 2.2 Rappresentazione grafica della Funzione di Ripartizione di \(X\) valutata nel punto \(7.2\), \(F(7.2)\) è l’area da 0 a 7.2 dell’istogramma.
Nel nostro caso \(F(7.2)\) è la comma delle frequenze fino a 5 più l’area del rettangolo di base \((7.2-5)\) e altezza \(h_3=4.4444/100\), ovvero \[\begin{eqnarray*} F(7.2) &=& f_1+f_2+\frac{(7.2-5)}{100}\times4.4444 \\ &=& F_2 +2.5\times0.0444\\ &=& 0.6533 \end{eqnarray*}\] Se per esempio ci interessasse sapere, in modo approssimato, che percentuale e quanti individui che guadagno meno di 7.2 (mila euro) al mese, basta moltiplicare \(F(7.2)\) per 100 e per \(n\), rispettivamente. \[\begin{eqnarray*} \%(X<7.2) &=& 100\times F(7.2) \\ &=& 65.3333\% \\ \#(X<7.2) &=& 45\times F(7.2) \\ &=& 29.4 \end{eqnarray*}\] Dove \(\%(X<7.2)\) significa la percentuale approssimata di dati minori di 7.2 e dove \(\#(X<7.2)\) significa il numero approssimato di dati minori di 7.2.
Se per esempio sono interessato alla percentuale (o al numero) di dati compresi tra 2.4 e 7.2 osservo che \[\begin{eqnarray*} \%(2.4<X<7.2) &=& 100\times (F(7.2)-F(2.4)) \\ F(2.4) &=& \frac{2.4-0}{100}\times6.6667 \\ &=&0.16\\ \%(2.4<X<7.2) &=& 100\times (0.6533-0.16) \\ &=& 49.3333. \end{eqnarray*}\] Infatti calcolare l’area tra 2.4 e 7.2 equivale a calcolare l’area fino a 7.2, l’area fino a 2.4 e sottrarle.
Più in generale la funzione di ripartizione cumula l’area dal più piccolo degli \(\text{x}\) fino al più grande.
\[\begin{eqnarray*} F(x) &=& 0 \quad \text{per ogni } x\le \text{x}_1\\ F(x) &=& F(\text{x}_{j^*-1}) + \frac{x-\text{x}_{j^*}}{100}h_{j^*}\\ F(x) &=& 1 \quad \text{per ogni } x\ge \text{x}_{K+1}\\ \end{eqnarray*}\]
dove \(j^*\) è la classe che contiene \(x\). Se la volessimo rappresentare graficamente, nel nostro esempio sarebbe così:
2.5 L’inversa della Funzione di Ripartizione
La funzione di ripartizione è una funziona che crescente che vale zero quando \(x\) è il più piccolo dei dati e vale uno quando \(x\) è il più grande dei dati. \[ F:S_X\to [0,1] \] Definiamo \(Q=F^{-1}\) la funzione inversa: \[ Q:[0,1]\to S_X \] ed è tale che \[ Q(p)=x_p:F(x_p)=p, 0\le p\le 1 \]
2.6 Indicatori Sintetici di Centralità e di Variabilità
Un indicatore è un numero che sintetizza una caratteristica del fenomeno collettivo. Esempi di indicatori sono: il massimo del fenomeno, il minimo del fenomeno, la media del fenomeno, la modalità più ricorrente, ecc.
Gli indicatori di centralità sintetizzano l’intero fenomeno in un numero. Indicatori di che osserveremo centralità sono:
- La media aritmetica (variabili quantitative) nella sezione 3.1
- La mediana (variabili quantitative e variabili qualitative ordinate) nella sezione 4.1
- La moda (ogni tipo di variabile) nella sezione 4.4
La media aritmetica è una media analitica perché dipende dal valore che la variabile assume sulle unità. Mediana e Moda sono invece medie lasche perché dipendono dall’ordinamento dei dati.
Gli indicatori di variabilità misurano lo scostamento del fenomeno oggetto di studio dall’indicatore di centralità. Vedremo:
2.7 Riepilogo
| Estremo inf | Estremo sup | freq. ass. | freq. relativa | freq. cum. | ampiezza | densità |
|---|---|---|---|---|---|---|
| \([\text{x}_1,\) | \(\text{x}_2)\) | \(n_1\) | \(f_1=\frac{n_1}{n}\) | \(F_1=f_1\) | \(b_1=\text{x}_2-\text{x}_1\) | \(h_1=100\times \frac{ h_1}{b_1}\) |
| \([\text{x}_2,\) | \(\text{x}_3)\) | \(n_2\) | \(f_2=\frac{n_2}n\) | \(F_2=F_1+f_2\) | \(b_2=\text{x}_3-\text{x}_2\) | \(h_2=100\times \frac{ f_2}{b_2}\) |
| \(...\) | \(...\) | \(...\) | \(...\) | \(...\) | \(...\) | \(...\) |
| \([\text{x}_j,\) | \(\text{x}_{j+1})\) | \(n_j\) | \(f_j=\frac{n_j}n\) | \(F_j=F_{j-1}+f_j\) | \(b_j=\text{x}_{j+1}-\text{x}_j\) | \(h_j=100\times \frac{ f_j}{b_j}\) |
| \(...\) | \(...\) | \(...\) | \(...\) | \(...\) | \(...\) | \(...\) |
| \([\text{x}_K,\) | \(\text{x}_{K+1})\) | \(n_K\) | \(f_K=\frac{n_K}n\) | \(F_K=F_{K-1}+f_K\) | \(b_K=\text{x}_{K+1}-\text{x}_K\) | \(f_K=100\times \frac{ f_K}{b_K}\) |